Hadoop 单机环境配置
撰写时间: 2020-09-10 总共: 2898 字 转载请注明: BY-SA 4.0(除特别声明或转载文章外)
Hadoop单机模式
仅记录 Hadoop 单机模式安装配置。
环境:Ubuntu18.04
相关软件安装
hadoop-2.7.5
open-jdk-8
openssh-server
简单记录安装hadoop
hadoop-2.7.5.tar.gz
# 解压
tar -zxvf hadoop-2.7.5.tar.gz
# 重命名
mv hadoop-2.7.5 hadoop
省略安装 jdk 与 openssh-server
添加环境变量
sudo vim /etc/profile
# 以下内容添加到文件结尾
# Java
export JAVA_HOME=/usr/lib/jvm/java-1.8.0-openjdk-amd64
export JRE_HOME=$JAVA_HOME/jre
export CLASS_PATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar:$JAVA_HOME/lib
# Hadoop
export HADOOP_HOME=/home/ubuntu/soft/hadoop
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export HADOOP_OPTS="-Djava.library.path=$HADOOP_HOME/lib"
export PATH=.:${JAVA_HOME}/bin:${HADOOP_HOME}/bin:$PATH
# add end
# 重载配置
source /etc/profile
修改Hadoop相关配置
主要涉及
hadoop/etc/hadoop文件夹下的 xml 配置文件。需要进行一个自定义临时文件和HDFS目录的创建,可自行选择,创建了如下文件目录,初始化后HDFS文件目录将会生成在这里。
cd /home/ubuntu/soft/hadoop/etc/hadoop
以下文件修改均位于该路径下进行。
core-site.xml
sudo vim core-site.xm
<property>
<!--HDFS-->
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000</value>
</property>
<property>
<!--tmp dir path-->
<name>hadoop.tmp.dir</name>
<value>/home/ubuntu/file/hadoop-data/tmp</value>
</property>
hdfs-site.xml
sudo vim hdfs-site.xml
<property>
<name>dfs.name.dir</name>
<value>/home/ubuntu/file/hadoop-data/dfs/name</value>
<description>Path on the local filesystem where theNameNode stores the namespace and transactions logs persistently.</description>
</property>
<property>
<name>dfs.data.dir</name>
<value>/home/ubuntu/file/hadoop-data/dfs/data</value>
<description>Comma separated list of paths on the localfilesystem of a DataNode where it should store its blocks.</description>
</property>
<property>
<!--HDFS存储时的备份数量-->
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<!--false可以允许不要检查权限就生成dfs上的文件-->
<name>dfs.permissions</name>
<value>false</value>
<description>need not permissions</description>
</property>
mapred-site.xml
需要进行复制一份模版
cp mapred-site.xml.template mapred-site.xml
sudo vim mapred-site.xml
<property>
<name>mapred.job.tracker</name>
<value>localhost:9001</value>
</property>
<property>
<name>mapred.local.dir</name>
<value>/home/ubuntu/file/hadoop-data/var</value>
</property>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
hadoop-env.sh
sudo vim hadoop-env.sh
# 将JAVA_HOME 进行替换为自己的JAVA_HOME
export JAVA_HOME=/usr/lib/jvm/java-1.8.0-openjdk-amd64
启动Hadoop
初始化HDFS
第一次需初始化HDFS
cd /home/ubuntu/soft/hadoop/bin
./hadoop namenode -format
未进行ssh的启动或者ssh server的安装,这里会出现连接失败的问题
初始化完成后,可以在dfs文件下看见 current 目录以及一些文件
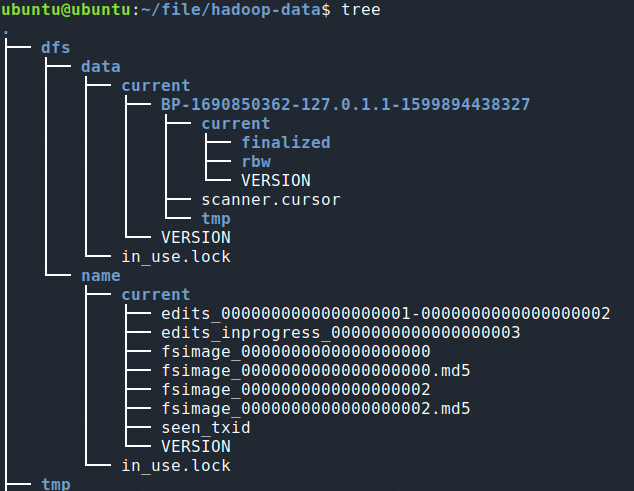
完毕之后进入 /sbin 下
启动
cd /home/ubuntu/soft/hadoop/sbin
# 启动 all
./start-all.sh
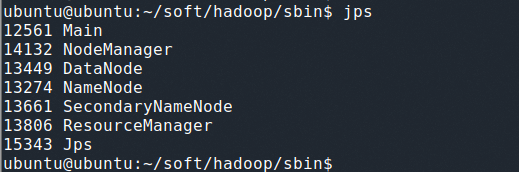
完成后可 jps 查看运行中的 Java 进程
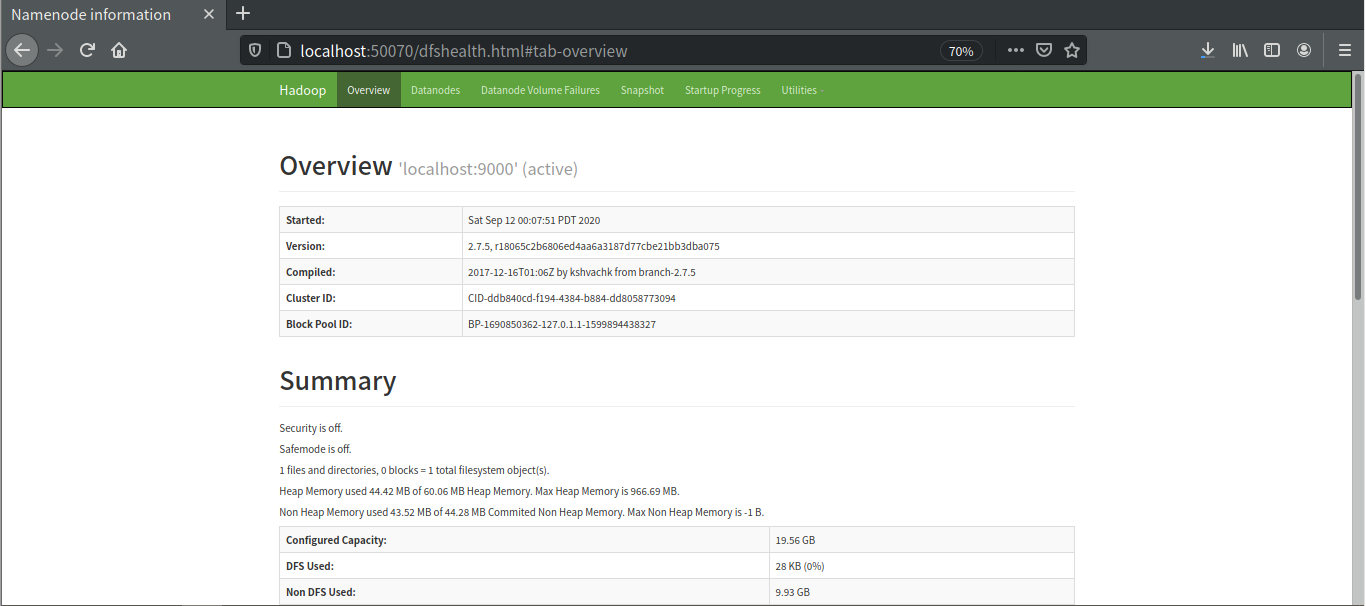
web客户端
Yarn:端口号是8088,查看当前执行的job。
http://localhost:8088/cluster
HDFS:端口号是50070
http://localhost:50070